
DLI 示範課程:建立 GPU 加速的檢索增強生成 (RAG) 流程
杜承翰, 資深解決方案架構師, NVIDIA
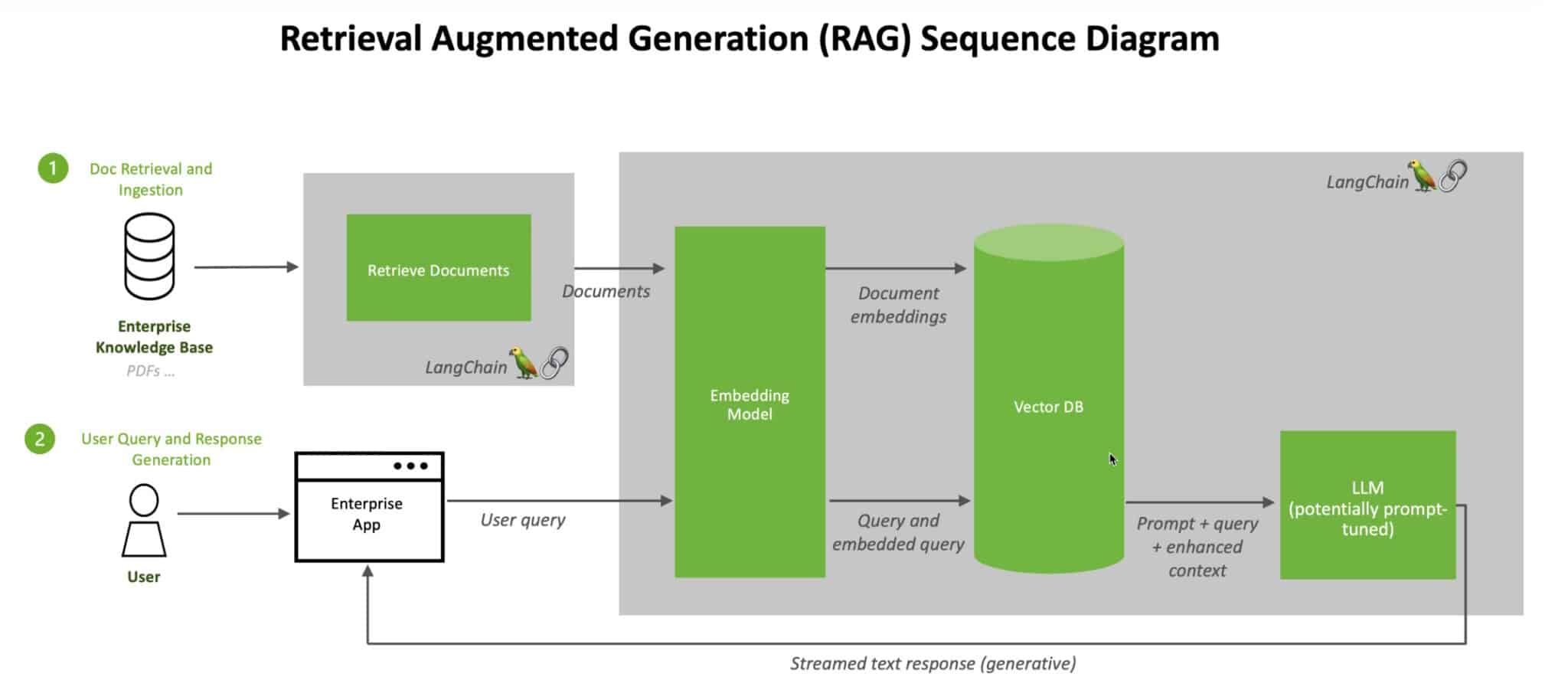
RAG Sequence Diagram (source: https://blogs.nvidia.com.tw/blog/what-is-retrieval-augmented-generation/)
講師介紹了檢索增強生成 (RAG) 的框架,並透過 LangChain 程式碼進行實作,介紹如何建立一個完整的 RAG 流程。langchain-nvidia-ai-endpoints 整合了 LangChain 功能,可使用 NVIDIA NIM 微服務上的模型建構 applications。
RAG 的流程包括:
- 資料預處理
- 索引與檢索
- 透過 LLM 生成結果
LLM 的限制
LLM 雖然強大,但可能存在以下限制:
- 過時的訓練資料
- 特定領域知識不足
- 幻覺
- 偏差資訊
RAG 提高 LLM 可靠性
檢索增強生成 (RAG) 是一種技術/過程,透過使用外部資料來提高生成式 AI 模型的準確性和可靠性。在企業應用範疇中,將 LLM 連接到企業資料,可以生成最新的特定領域答案。其優勢包括:
- 與企業資料的交流
- 保護資料隱私
- 減輕 LLM 的幻覺
- 讓 LLM 優先使用相關資訊,無需重新訓練或微調模型
NVIDIA NEMO
RAG 生態系統非常複雜,企業必須整合、更新和維護開源解決方案。使用 NVIDIA NeMo 可以最佳化 RAG 應用程式。
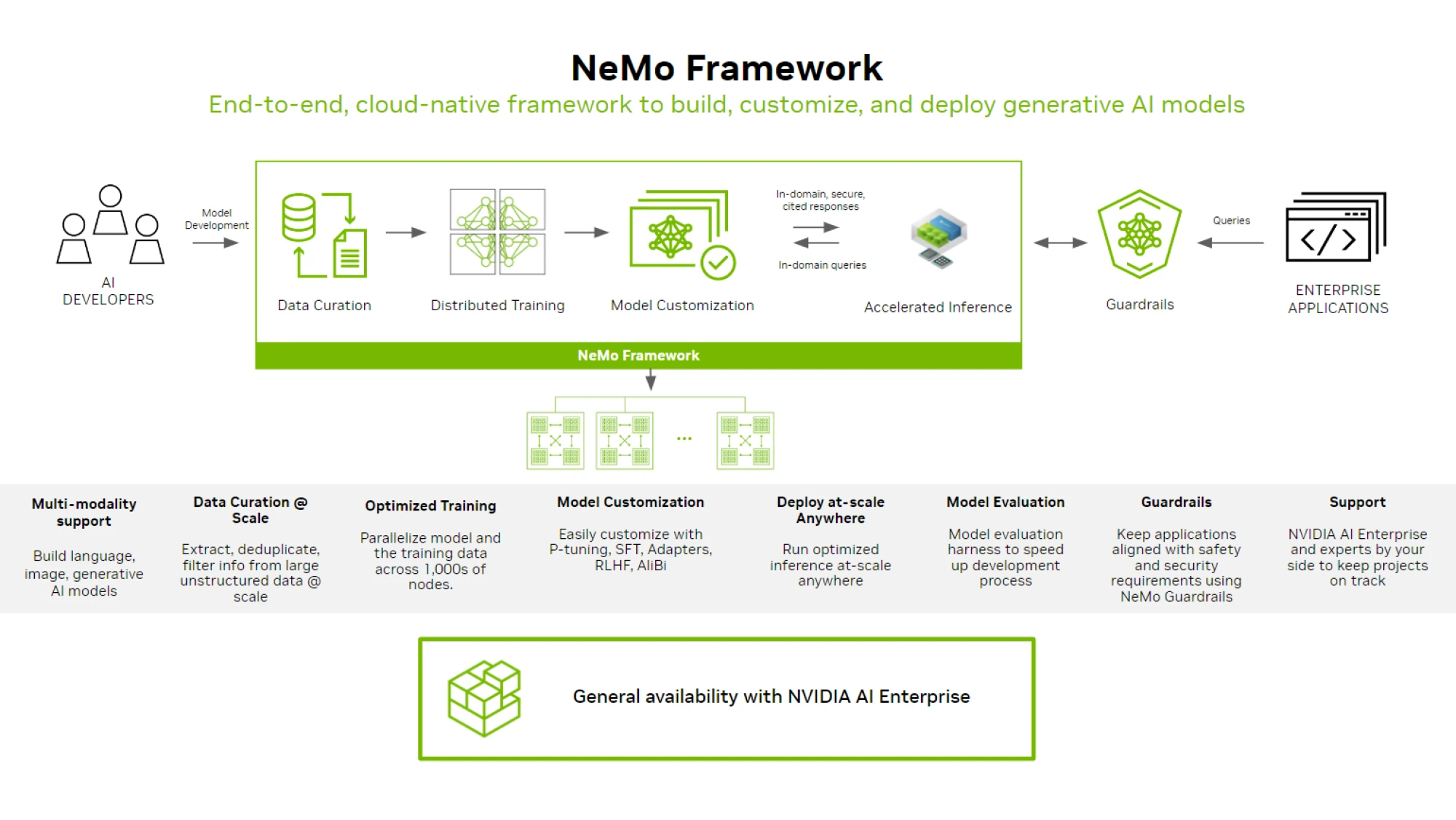
NeMo Framework (source: https://docs.nvidia.com/nemo-framework/index.html)
評估 RAG 系統
建造出服務後,往往會碰到一個問題:如何評估模型好壞。講者介紹了以下兩種 RAG 評估方式,判斷生成結果的相關性和正確性。
- TruLens: TruLens 提供 TruRails 工具,與 NeMo Guardrails 應用程式整合,可用於評估生成結果。
- RAGAS: RAGAS 可以使用 LangChain 來連接 NVIDIA AI foundation model 和 endpoint 進行評估。
📖 延伸閱讀:TruLens, RAGAS 與其他評估方法
理解專利請求項附屬關係的自動生成模型
陳豐奇, 副所長, 國家衛生研究院
在 IPR (Inter Partes Review) 的過程中,專利會經過多方複審,涉及到案件、法官、當事人等。這些實體關係近似於 social network,可以用 Entity Relation 表徵。
專利請求項包括獨立項和附屬項,每一項都必須是單一完整的句子。附屬項越多,專利保護範圍越小。以下列例子說明:
- A device comprising an operating face of a front face of the device… (獨立項)
- The device according to claim 1… (附屬項)
- The device according to claim 2… (附屬項)
第一點是獨立項,第二和第三點是附屬項。
專利包含結構附屬 (structural dependency) 和技術附屬 (technical dependency) ,兩者都正確編寫才能形成有效的附屬項。LLM能否做到這一點呢?
由於專利數據無法上傳至雲端,使用地端 LLM 進行微調變得尤其重要。研究中使用了不同的開源 LLM 進行微調,並評估生成的專利請求項內文。其中一項評估方法是讓三位專利工程師進行盲測,人工驗證結果。結果顯示,地端微調的 LLM 得分幾乎與 GPT-4 相當。即使是較小的模型,經過微調後也能達到與大型 LLM 相同的效果,生成出具有正確寫作風格的專利請求項。
如何透過整合文化背景來改進大型語言模型建模
陳縕儂, 副教授, 國立台灣大學
Taiwan-LLM 的訓練方法旨在使模型本地化,結合台灣的文化背景,並加強繁體中文的支援,提升其在地應用效果。
台灣本土資料上進行持續預訓練
TAME (TAiwan Mixture of Experts) 計劃網羅各領域專家,蒐集來自媒體、法律、醫療、化工、製造業和遊戲等多個領域的本土資料。
- Model: Llama-3 8B & 70B
- Context Length: 8192
- Long Context Extension: 64k
- Training Framework: Nvidia NeMo, Nvidia NeMo Megatron
- Inference Framework: Nvidia TensorRT-LLM
- Hardware: Nvidia DGX H100 on Taipei-1
- Training Stack: 3D parallelism, DeepSpeed Zero, Flash Attention 降低記憶體用量並加速訓練
生成多輪 AI 對話資料進行微調
在繁體中文 LLM 競技場蒐集真實使用者的回饋,以進行模型微調。
真實使用者互動並微調
透過 Direct Preference Optimization (DPO) 方法,根據使用者的偏好計算 maximum likelihood,最終微調 LLM。
LLM 評估
Open Taiwan LLM Leaderboard 展示了各模型在不同任務上的表現。評估測試集包含:
- TMLU: 衡量模型理解各個領域 (國中、高中、大學、國考) 的能力。
- TW Truthful QA: 評估模型以臺灣特定背景回答問題的能力。
- TW Legal Eval: 評估模型對臺灣法律術語和概念的理解。
- MMLU: 測試模型在英語各種任務上的表現。
探討繁中大型語言模型建構之挑戰與克服
陳宜昌, 聯發創新基地
許大山, 創新基地負責人, 聯發科技
聯發科與 NVIDIA 持續合作,Breeze-7B 和 BreeXe-8x7B 已上架 NVIDIA Inference Microservice (NIM) 。Breeze 模型在訓練中僅使用 2 台 H100,其性能已接近於使用 10 倍算力的 Llama3。
挑戰與克服
缺乏 benchmark
MediaTek Research 發布了 TC-Eval 繁體中文 LLM benchmark,提供一個全面的評估標準。缺乏大規模的預訓練數據
Common Crawl 是一個龐大的公開網絡爬蟲數據集,截至 2023 年 12 月,數據量達到 454 TB。但繁體中文的資料還是非常少。- 英文:44%
- 簡體中文:5%
- 繁體中文:0.1%
MediaTek Research 通過多種方法收集了 1 TB 的臺灣繁體中文數據。
開源模型中支援的繁中 vocabularies 也非常少:
- LLaMA2: 563 out of 32k
- Mistral: 1034 out of 32k
MediaTek Research 開發了技術,將繁體中文的 vocabularies 擴展到超過 32k。
Breeze-7B
- 免費開源
- Source Model: Mistral 7B
- 繁體中文 vocabulary size 提升到 62k
- Inference 速度提高 2%
- 繁中 context length 達到 11.1k,相當於 10 頁文本
- 使用總計 7,000 小時 H100 預訓練 650 GB 的資料
BreeXe-8x7B
- Source Model: Mistral 8x7B (混合專家模型,Mixture of Experts, MoE)
- 繁體中文 vocabulary size 提升到 62k
- BreeXe 的對話能力與 GPT3.5 相當
- BreeXe 在台灣知識方面優於 GPT3.5
Breezper
使用 Generative Fusion Decoding (GFD) 技術,以 Breeze-7B + Whisper 打造語音模型。
- 提升同音字辨識率
- 提升 code switching 辨識率
- 實現 contextual-aware ASR
鴻海 GenAI 戰略
栗永徽, 所長, 鴻海研究院
鴻海 AI 戰略全力投入基礎模型技術,目標打造全方位解決方案平台。憑藉鴻海集團即將建置的龐大算力,人工智慧研究所將為集團研發 FoxBrain,作為三大平台底層最重要的智慧核心。三大平台為:
- Smart Manufacturing 智慧製造
- Smart EVs 智慧電動車
- Smart City 智慧城市
基礎模型細節
- 輕量高效的 LLM:實現更快的運算速度和更低的能耗。
- 人類偏好對齊:確保模型能夠對齊人類偏好,並設置 model guardrail 以防止不當生成。
- 多模態能力:增強模型在多種模態下的表現能力,包括視覺和語音的綜合應用。
FoxBrain 目標
- 多模態 AI 代理人
- 視覺-語言 (VLM)
- 自駕助手 (CabinGPT)
- 音頻-視覺-語言 (FoxBot 機器人)
- 特定領域 AI 專家模型
- 智慧醫療
- 智慧辦公室
- 智慧工廠
- 智慧城市
訓練過程透過 NVIDIA 工具優化
- 數據構建階段:NVIDIA NeMo Curator
- 自動化清理、轉換和分析數據
- 透過優化算法提升處理速度
- 模型訓練階段:NVIDIA NeMo Megatron
- 在高品質數據上繼續預訓練
- 在各種下游 NLP 任務上進行微調
- 模型部署階段:NVIDIA Triton 推論服務器
- 優化 neural network 以加快執行速度
- 低延遲,提升性能