
最近在老師的研究安排下讀了 How to do Linguistics with
R 的第十二章 Probabilistic
multifactorial grammar and lexicology: Binominal logistic
regression。本章介紹了如何以 logistic regression
解釋並預測兩個近似詞的使用情形。接下來將使用 Rling 中的資料集 nerd
做練習。
| |
取得 Rling 中的資料集 nerd
| |
資料視覺化
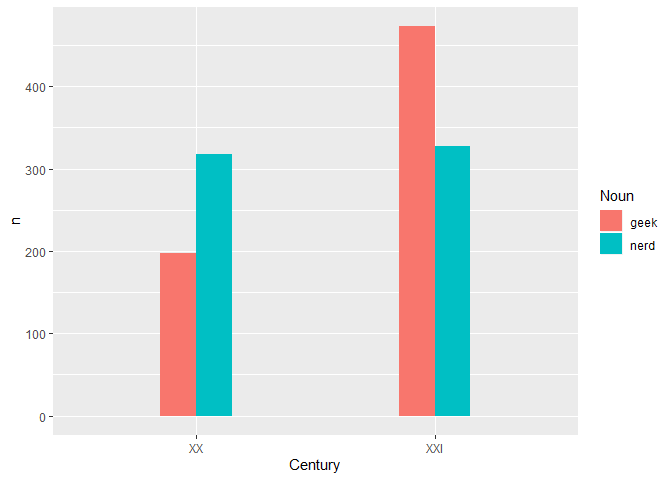
由下圖所示,在 20 世紀時,nerd 出現的次數比 geek 多。但在 21
世紀,geek 的使用次數超過前一世紀的兩倍,而 nerd
在兩世紀的次數無明顯差異,因此 geek 在 21 世紀的出現次數超過 nerd。
| |
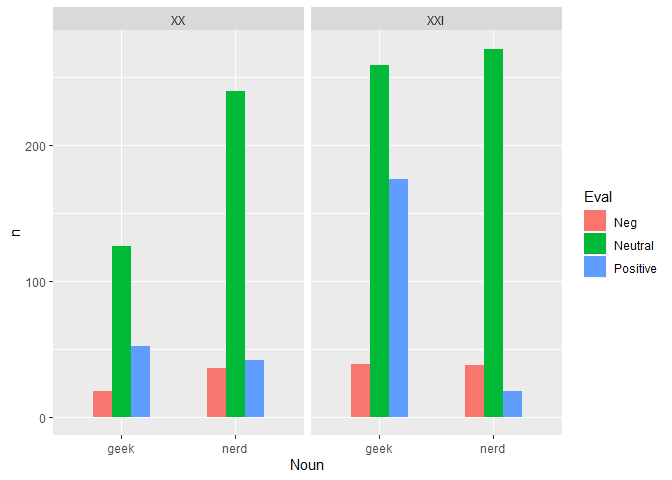
接下來看看不同世紀使用 nerd 與 geek 時的 polarities。可以發現不論在
20 或 21 世紀,使用 nerd 和 geek 時大部分都是 neutrual
polarity。特別的是,geek 在 21 世紀時被使用於 positive polarity
的次數很高。
| |
因為好奇,到 Cambridge Dictionary 上查了兩字的釋義:
nerd (n.)
(1) a person, especially a man, who is not attractive and is awkward or socially embarrassing
(2) a person who is extremely interested in one subject, especially computers, and knows a lot of facts about it
geek (n.)
someone who is intelligent but not fashionable or popular
看起來 geek 似乎真的比 nerd 還來得正面一些,至少有 intelligent
的部分~
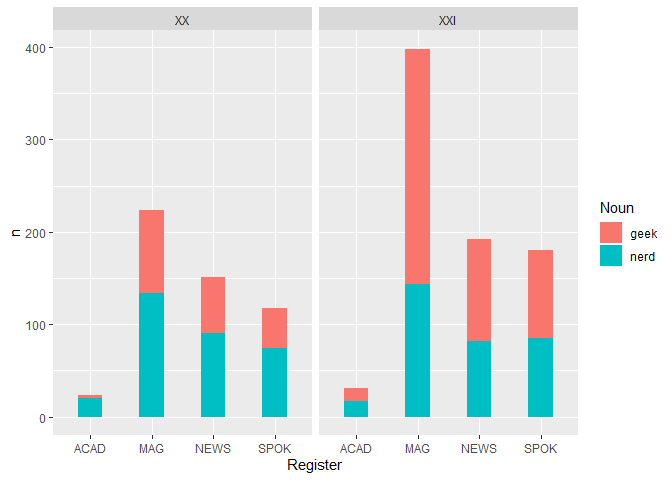
再看看兩詞在不同領域中的使用情形。在 20 與 21 世紀,geek 和 nerd
出現次數於學術領域最少,雜誌最多,而新聞又比口語多一些。且 21 世紀時,
geek 在雜誌出現的次數增加許多。
| |
Logistic Regression Model
試著用書上的方式 (p.258) 跑 lrm。
| |
Model Likelihood Ratio Test
從 Model Likelihood Ratio Test 的欄位中,可以得知 p-value 小於
0.05,代表這個 model 的顯著。
Discrimination Indexes
在 Discrimination Indexes 欄中可以看到 R2 值。R2 值介於 0 和 1
之間,這個 model 的 R2 值為 0.171,代表預測能力低。但書中提到 logistic
regression 的 R2 值通常會比 linear regression models
的來得低,因此並不建議採用 R2 值作為評斷。
Rank Discrim. Indexes
在 Rank Discrim. Indexes 欄中,C 代表 concordance index
(一致性指數),說明
model 的預測能力。表中可見 C = 0.687,預測能力普通。
Coef
接著來到 Coef 欄。以變數 Register 為例,ACAD 是 reference
level,因此不在表上。與 ACAD 差異最大的是 MAG(Coef =
-0.7457),其中 p = 0.0201 (<0.05) 代表顯著。
Century=XXI 的 Coef = -0.8063,表示 nerd 對 geek 的 odds 在 21
世紀降低了。也可以說,geek 在 21 世紀時出現次數較 nerd 頻繁。
相較於 Eval=Neutral,Eval=Positive 的 Coef 更小且為負數,表示 geek
在使用上較 nerd 有更多 positive connotation。
Num=sg 的 Coef = -0.2724,表示 geek 較 nerd 更常以單數出現。
Murmuring
照著書上的步驟跑了一個 Logistic Regression Model,但卻不大懂數值所代表的意義,重複讀了很多遍才稍微了解一點點。統計知識真的要補足啊!
Photo by James Pond on Unsplash